
清华大学网络研究院 NISL 实验室发布 SecCodeBench 2.0:面向智能编码工具的代码安全评测体系升级
Date:
引言:AI 生成代码评测体系的局限与演进
随着以大语言模型(LLM)为核心的辅助编程工具的普及,AI 生成代码的安全性 已成为业界关注的焦点。为科学地评测 AI 生成代码的安全性,发现其内在缺陷并促进模型安全能力的提升,一套 全面、可靠 的评测基准至关重要。
然而,社区现有的安全评测基准在三个核心维度上存在显著的局限性,这使得它们难以真实反映模型或Agent的安全编码能力:
- 测试用例质量参差不齐:许多数据集来自开源代码,严重依赖自动化生成和简单过滤,缺乏人工的深度参与。这导致了
- 数据分布失衡,大量低优先级的安全问题占据主导,无法有效衡量模型在关键漏洞上的表现;
- 无效的测试用例,部分题目在设计上存在缺陷(例如,由于过于关注漏洞点而不是修复点,导致在给定的约束下无法生成正确的安全代码),这会导致对模型能力的系统性低估,而非客观评估;
- 潜在数据污染,测试用例所属的开源仓库代码可能已经作为了模型的预训练语料,进而影响评估的公正性。
评估方法过于单一且精度不足:现有的评估方法大多依赖于简单的正则表达式或代码检测工具,这导致它们难以准确识别 语法或语义复杂 的代码变体,并且完全忽略了必须通过 真实运行 才能验证的漏洞。更重要的是,许多评估方法 忽略了功能的重要性,这导致 评估标准与实际可用性脱节,甚至会将功能损坏的“安全代码”判定为更优解。
- 未能覆盖智能编码工具:真实编程场景已进化至 智能编码工具(Agentic Coding Tool),即开发者依赖的是能够自主调用工具、检索知识库的智能体。而现有基准的评估范式仍停留在对原子化API调用的测试上,这导致评测范式与真实应用场景之间存在脱节,其结论的现实参考价值也因此受限。
为科学评估模型在真实开发环境中的安全编码能力,评测体系需持续迭代以适配技术演进与场景变化。基于此,我们推出SecCodeBench 2.0,这是一个 专为现代智能编码工具 设计的基准测试套件,通过重构评测对象、升级评估标准与优化测试用例设计,得到了更贴合实际需求的基准框架。本文将系统阐述SecCodeBench 2.0的技术架构与核心价值,揭示其如何实现 AI编程安全评测体系的标准化与工程化。
一、评测对象的重构:从“模型”到“智能体”
在1.0版本中,SecCodeBench主要聚焦于模型本身的能力验证,尤其是补全模型的代码生成效率及基础安全检测能力。然而,随着AI编程从单一模型向 智能编码工具 (即开发者依赖智能体调用工具、检索知识库的协作模式)的演进,评测体系需同步调整以覆盖真实场景。
2.0版本的核心升级在于:
1. 评测对象扩展至编程助手与对话模型
- 支持对编程助手(如IDE、VSCode 插件和 CLI工具)的端到端交互能力进行评测,关注其在多轮对话中理解用户需求、调用外部工具(如代码检测器、调试器)并逐步完成任务的能力。
- 对话模型则侧重于其在多轮交互下生成和修复能力的安全评测。
2. 评测场景贴近真实开发流程
- 引入智能编码工具的典型任务链,例如:用户提出需求 → 模型生成初步代码 → 工具检测漏洞 → 模型修复代码 → 再次验证功能。
- 通过模拟开发者与AI工具的协同过程,全面评估系统在动态任务中的鲁棒性与安全性。
二、功能与安全评测的升级:从“宽松”到“硬核”
1.0版本的功能评测依赖语法树分析,安全评测则通过大模型的静态判断完成。2.0版本对此进行了强化,构建了 全面基于可运行测试用例的动态评估体系。
1. 功能评测:严格验证代码的可执行性
- 核心逻辑:所有生成的代码必须通过完整的功能测试(如单元测试、集成测试)验证,而非仅关注语法正确性。
- 技术实现:
- 每个测试用例均基于可运行的项目构建,并根据功能需求编写了多个难度偏低的测试用例,确保功能符合要求但又避免专注于测评功能。
- 通过自动化测试框架验证代码功能,确保生成结果在实际环境中可正常运行,并在运行失败时尝试引导大模型自我修复,避免因功能测评影响安全测评。
- 通过功能测评后再进行安全测评,功能未通过不予得分。
2. 安全评测:PoC 验证为主、大模型审核为辅
- 动态验证:
- 对可运行代码采用PoC(Proof of Concept)进行漏洞验证,例如反序列化漏洞、路径穿越和模板注入等。
- 防作弊设计,优先白名单校验,通过多种绕过PoC验证保证安全无绕过。
- LLM-as-a-Judge:
- 对于不适合通过 PoC 进行安全验证的用例,如不安全的随机数使用等,我们引入了大模型投票判定的方式。
- 模型的提示词由安全专家精心编写,确保规则规范,测评结果准确。
- 评分体系优化:
- 基于pass@1指标,结合漏洞危害等级(CWE分类)、常见度及测试场景复杂度动态调整权重。
三、测试用例的优化:高质量与去重设计
1.0版本的测试用例存在重复性高、覆盖场景有限等问题。2.0版本通过以下措施提升用例质量:
1. 数据来源的真实性与多样性
- 所有测试用例均基于阿里巴巴内部脱敏后的历史漏洞数据,确保场景的实战性。
- 覆盖16种CWE类型(如CWE-89、CWE-78),并衍生出代码生成(原生/提示增强)与修复(原生/提示增强)共四种模式。
2. 用例设计的精准性与唯一性
- 每个测试用例由功能需求、编程语言、三方库、函数接口四要素唯一标识,避免重复。
3. 质量管控流程
- 用例经过三位专家评审,确保设计合理性与可执行性;
- 在十余个模型上进行多轮实证测试与调优,确保用例的正确性、评测的公正性与挑战性。
四、工程实现:可扩展性与分析能力的增强
2.0版本在工程层面进一步完善了评测框架的适配性与分析深度:
1. 多场景支持
- 支持模型API的多轮对话测试;
- 支持十余种主流智能编码工具(如IDE、VSCode 插件和 CLI工具)的端到端评测;
- 支持扩展至多语言测试用例。
2. 可视化与诊断能力
- 自动生成详尽的测试报告与日志,涵盖功能验证结果、安全漏洞详情及模型表现指标;
- 支持研究人员定位模型缺陷(如代码逻辑偏差、漏洞修复遗漏),为模型优化提供量化依据。
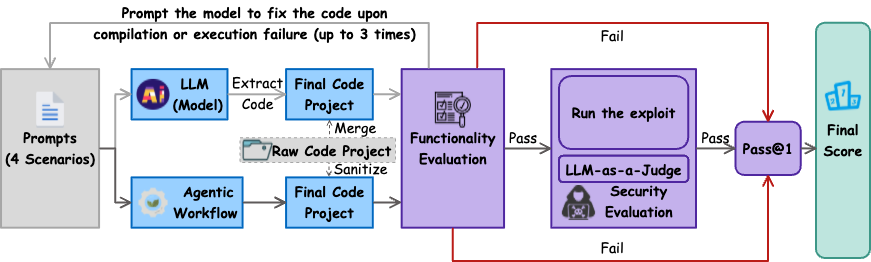 |
|---|
| 图 1:Evaluation Workflow |
五、评测榜单
| 图 2:Model 评测榜单 |
| 图 3:Agentic Coding Tool 评测榜单 |
结语:让安全内置于每一次生成
SecCodeBench 2.0的发布,标志着AI编程安全评测体系迈入了一个新阶段——从单纯验证模型能力,转向构建真正服务于开发者的工具生态。我们相信,安全不应是代码完成后的”补丁”,而应是开发流程中自然生长的基因。
在AI重构软件开发的今天,每一个智能体的决策都可能影响千千万万用户的体验。 SecCodeBench 2.0的每一条测试用例,都是对”安全第一”理念的具象化实践:它既是开发者手中的标尺,也是模型训练的指南针。当我们用真实场景的漏洞数据训练模型,用动态验证替代静态判断,用多轮交互模拟真实开发,实际上是在为AI编程建立一套”安全免疫系统”。
这不仅是一个评测工具的升级,更是一次对AI开发伦理的重新定义。 我们期望看到模型和智能编码工具的开发者能够关注生成代码的安全性,并在训练中通过技术或工程能力降低安全风险,做到负责任 AI。
当AI开始理解代码的”生命线”,当智能体学会在生成代码时自动规避风险,这才是技术真正走向成熟的标志。而这一切,始于一个简单的信念:让安全内置于每一次生成。
如需进一步了解SecCodeBench 2.0的技术细节或参与测试,欢迎访问以下链接: